
Compartilhe minha pesquisa é a coluna da Synced, que recebe os estudiosos para compartilhar suas próprias pesquisas com mais de 2M entusiastas da IA global. Além dos avanços tecnológicos, compartilhar minha pesquisa também exige histórias interessantes por trás da pesquisa e das idéias emocionantes de pesquisa.
Conhecer o autor
Instituições: Penn State University, Duke University, Google Deepmind, Universidade de Washington, Meta, Universidade Tecnológica de Nanyang e Universidade Estadual de Oregon. Os autores co-primeiro são Shaokun Zhang, da Penn State University e Ming Yin, da Duke University.
Nos últimos anos, os sistemas multi-agentes da LLM chamaram a atenção generalizada por sua abordagem colaborativa para resolver problemas complexos. No entanto, é um cenário comum para esses sistemas falharem em uma tarefa, apesar de uma enxurrada de atividade. Isso deixa os desenvolvedores com uma pergunta crítica: qual agente, em que momento, foi responsável pelo fracasso? Examinar os vastos toras de interação para identificar a causa raiz parece encontrar uma agulha em um palheiro-um esforço demorado e de trabalho intensivo.
Esta é uma frustração familiar para os desenvolvedores. Em sistemas multi-agentes cada vez mais complexos, as falhas não são apenas comuns, mas também incrivelmente difíceis de diagnosticar devido à natureza autônoma da colaboração do agente e das cadeias de informações longas. Sem uma maneira de identificar rapidamente a fonte de uma falha, a iteração do sistema e a otimização de interrupção para parar.
Para enfrentar esse desafio, pesquisadores de Universidade Penn State e Universidade Dukeem colaboração com instituições, incluindo Google DeepMindintroduziram o novo problema de pesquisa de “Atribuição de falha automatizada.” Eles construíram o primeiro conjunto de dados de referência para esta tarefa, Quem e quandoe desenvolveram e avaliaram vários métodos de atribuição automatizados. Este trabalho não apenas destaca a complexidade da tarefa, mas também abre um novo caminho para melhorar a confiabilidade dos sistemas multi-agentes LLM.
O artigo foi aceito como um Apresentação de destaque na conferência de aprendizado de máquina de primeira linha, ICML 2025e o código e o conjunto de dados agora estão totalmente abertos.
Papel : https: //arxiv.org/pdf/2505.00212
Código : https: //github.com/mingyin1/agents_failure_attribution
DataSet: https: //huggingface.co/datasets/kevin355/who_and_when
Antecedentes de pesquisa e desafios
Sistemas multi-agentes orientados por LLM demonstraram imenso potencial em muitos domínios. No entanto, esses sistemas são frágeis; Erros por um único agente, mal -entendidos entre agentes ou erros na transmissão de informações podem levar à falha de toda a tarefa.
Atualmente, quando um sistema falha, os desenvolvedores geralmente ficam com métodos manuais e ineficientes para depuração:
Arqueologia manual de log : Os desenvolvedores devem revisar manualmente os longos logs de interação para encontrar a fonte do problema.
Confiança na experiência : O processo de depuração é altamente dependente da profunda compreensão do desenvolvedor do sistema e da tarefa em questão.
Essa abordagem de “agulha em um palheiro” da depuração não é apenas ineficiente, mas também dificulta severamente a iteração rápida do sistema e a melhoria da confiabilidade do sistema. Existe uma necessidade urgente de um método sistemático automatizado para identificar a causa das falhas, na ponte efetivamente da lacuna entre “resultados de avaliação” e “melhoria do sistema”.
Contribuições principais
Este artigo faz várias contribuições inovadoras para enfrentar os desafios acima:
1. Definindo um novo problema: O artigo é o primeiro a formalizar a “atribuição de falha automatizada” como uma tarefa de pesquisa específica. Esta tarefa é definida pela identificação do
2. Agente responsável por falhas e o Etapa de erro decisiva Isso levou ao fracasso da tarefa.
Construindo o primeiro conjunto de dados de referência: quem e quando : Este conjunto de dados inclui uma ampla gama de logs de falhas coletados de 127 sistemas multi-agentes LLM, que foram gerados algoritmicamente ou artesanais por especialistas para garantir realismo e diversidade. Cada log de falhas é acompanhado por anotações humanas de granulação fina para:
Quem: O agente responsável pela falha.
Quando: A etapa de interação específica onde ocorreu o erro decisivo.
Por que: Uma explicação da linguagem natural da causa do fracasso.
3. Explorando os métodos iniciais de “atribuição automatizada”: usando o conjunto de dados OMS e quando, o papel projeta e avalia três métodos distintos para atribuição automatizada de falhas:
All-at-Once: Este método fornece ao LLM a consulta do usuário e o log de falhas completo, pedindo para identificar o agente responsável e a etapa de erro decisiva em um único passe. Embora econômico, pode lutar para identificar erros precisos em contextos longos.
Passo a passo: Essa abordagem imita a depuração manual ao fazer a revisão do LLM o log de interação sequencialmente, fazendo um julgamento em cada etapa até que o erro seja encontrado. É mais preciso localizar a etapa de erro, mas incorre em custos e riscos mais altos acumulando erros.
Pesquisa binária: Um compromisso entre os dois primeiros métodos, essa estratégia divide repetidamente o log pela metade, usando o LLM para determinar qual segmento contém o erro. Em seguida, pesquisa recursivamente o segmento identificado, oferecendo um equilíbrio de custo e desempenho.
Resultados experimentais e descobertas -chave
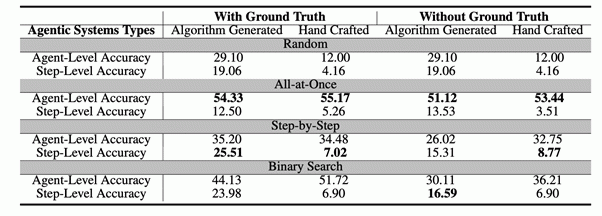
As experiências foram realizadas em duas configurações: uma em que o LLM conhece a verdade da verdade, a resposta para o problema que o sistema multi-agente está tentando resolver (Com a verdade do solo) e um onde não o faz (Sem verdade fundamental). O modelo principal utilizado foi o GPT-4O, embora outros modelos também tenham sido testados. A avaliação sistemática desses métodos no OMS e quando o conjunto de dados produziu várias informações importantes:
- Um longo caminho a percorrer: Os métodos atuais estão longe de ser perfeitos. Até o método único de melhor desempenho alcançou uma precisão apenas sobre 53,5% Ao identificar o agente responsável e um mero 14,2% Ao identificar a etapa de erro exata. Alguns métodos tiveram um desempenho ainda pior do que adivinhação aleatória, ressaltando a dificuldade da tarefa.
- Nenhuma solução “all-in-one”: Diferentes métodos se destacam em diferentes aspectos do problema. O All-at-Once o método é melhor em identificar “quem”, enquanto o Passo a passo O método é mais eficaz para determinar “quando”. O Pesquisa binária O método fornece um desempenho intermediário.

- As abordagens híbridas mostram promessas, mas a um alto custo: Os pesquisadores descobriram que a combinação de diferentes métodos, como o uso da abordagem de tudo o que é para identificar um agente em potencial e, em seguida, aplicar o método passo a passo para encontrar o erro, pode melhorar o desempenho geral. No entanto, isso vem com um aumento significativo no custo computacional.

- Os modelos de última geração lutam: Surpreendentemente, mesmo os modelos de raciocínio mais avançados, como Openai O1 e Deepseek R1encontre esta tarefa desafiadora. Isso destaca a dificuldade inerente da atribuição automatizada de falhas, que exige um nível mais alto de raciocínio do que o necessário para tarefas mais convencionais.
- A importância do raciocínio explícito: Fornecer instruções explícitas que exigem que o LLM explique seu raciocínio nos métodos de tudo e passo a passo, demonstrou melhorar o desempenho.


- O comprimento do contexto é um fator limitante: O estudo também revelou que, à medida que o comprimento do contexto dos logs de falha aumenta, o desempenho de todos os métodos de atribuição tende a diminuir, com um impacto mais pronunciado na precisão da identificação da etapa de erro.
