

No início de junho, os pesquisadores da Apple divulgaram um estudo sugerindo que os modelos simulados de raciocínio (SR), como OpenAI’s O1 e O3, Deepseek-R1 e Claude 3,7 sonetos pensando, produzem saídas consistentes com a correspondência de padrões a partir de dados de treinamento quando enfrentados por novos problemas que requerem pensamento sistemático. Os pesquisadores encontraram resultados semelhantes a um estudo recente dos Estados Unidos de Olimpíada matemática da América (USAMO) em abril, mostrando que esses mesmos modelos alcançaram baixas pontuações em novas provas matemáticas.
O novo estudo, intitulado “A ilusão do pensamento: entender os pontos fortes e limitações dos modelos de raciocínio por meio da lente da complexidade do problema”, vem de uma equipe da Apple liderada por Parshin Shojaee e Iman Mirzadeh, e inclui contribuições de Keivan Alizadeh, Maxwell Horton, Samy Bengio e Mehrdar Farajtabar.
Os pesquisadores examinaram o que chamam de “grandes modelos de raciocínio” (LRMS), que tentam simular um processo de raciocínio lógico, produzindo uma saída de texto deliberativa às vezes chamada de “raciocínio da cadeia de pensamento” que auxilia ostensivamente na solução de problemas de uma maneira passo a passo.
Para fazer isso, eles colocaram os modelos de IA contra quatro quebra -cabeças clássicos –Torre de Hanói (Discos em movimento entre pinos), piscinas de damas (eliminando peças), cruzamento de rios (transportando itens com restrições) e bloqueia o mundo (bloqueios de empilhamento)-escalando-os de trivialmente fáceis (como um disco único Hanói) para extremamente complexo (20-disco Hanói exigindo mais de um milhão de movimentos).
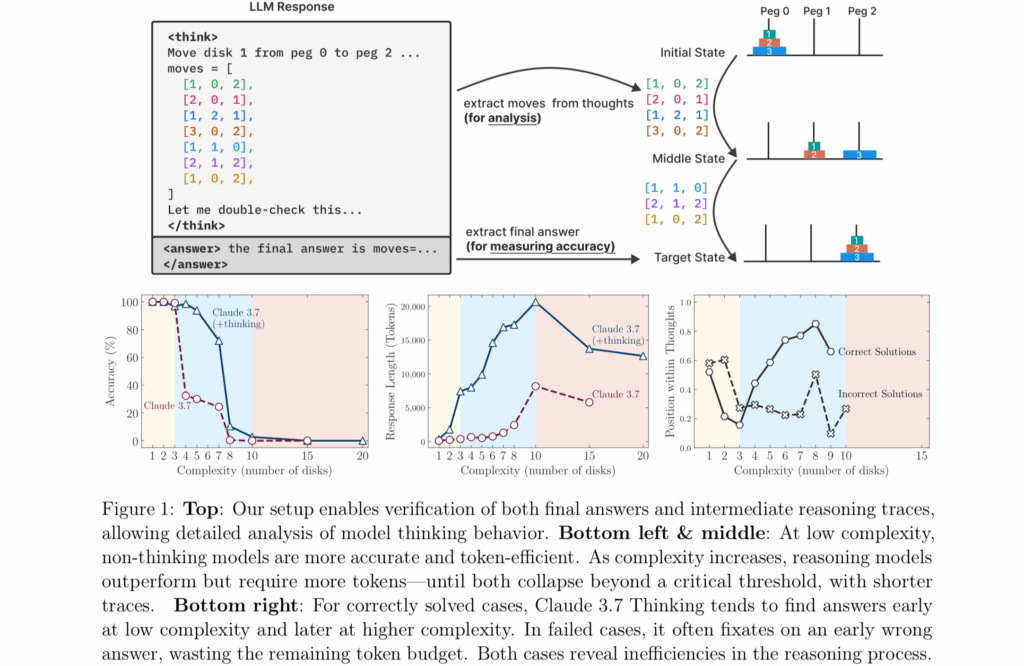
Figura 1 do artigo de pesquisa “The Illusion of Thinking” da Apple.
Crédito: Apple
“As avaliações atuais se concentram principalmente nos benchmarks matemáticos e de codificação estabelecidos, enfatizando a precisão da resposta final”, escrevem os pesquisadores. Em outras palavras, os testes de hoje se importam apenas se o modelo receber a resposta certa para problemas de matemática ou codificação que já podem estar em seus dados de treinamento-eles não examinam se o modelo realmente se baseou nessa resposta ou simplesmente correspondente a padrões de exemplos que já havia visto antes.
Por fim, os pesquisadores encontraram resultados consistentes com a pesquisa da USAMO acima mencionada, mostrando que esses mesmos modelos alcançaram principalmente menos de 5 % em novas provas matemáticas, com apenas um modelo atingindo 25 % e não uma única prova perfeita entre quase 200 tentativas. Ambas as equipes de pesquisa documentaram severa degradação do desempenho em problemas que exigem raciocínio sistemático prolongado.